


What building a Slack-driven agent for my own publishing system taught me about where the real engineering in agentic AI actually lives. Last month I gave an external AI agent the keys to a production system I run every day, and the most important line of code I wrote was the one I didn't write.
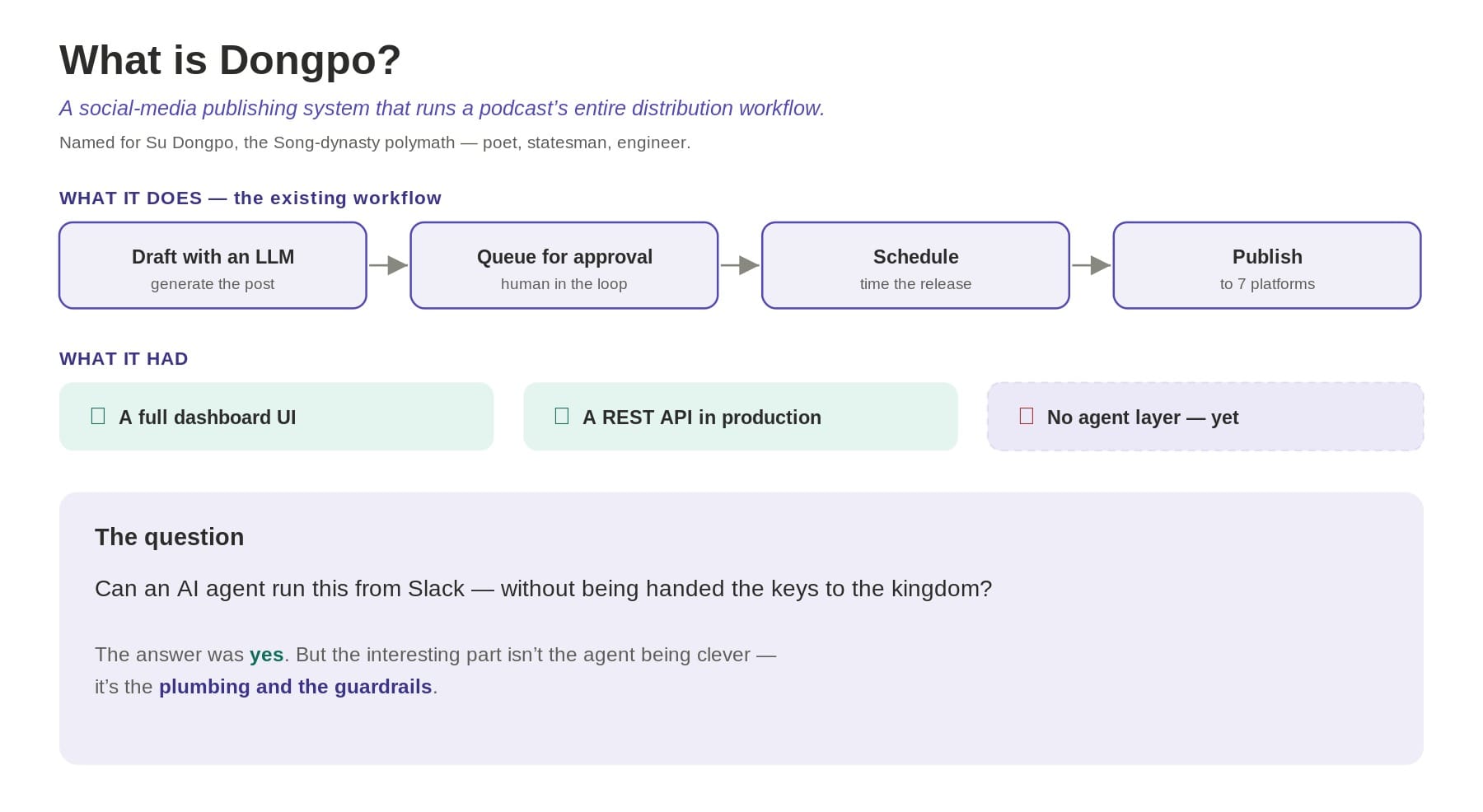
The system is called Dongpo named after a famous Chinese poet, Su Shi in the Song Dynasty. It is the social-media publishing pipeline behind the Analyse Podcast — it drafts posts with an LLM, queues them for human approval, schedules them, and publishes to seven platforms. It already had a dashboard, a REST API, and a database. I wanted to know one thing: could an off-the-shelf agent run this from Slack without being handed the keys to the kingdom?
The answer is yes. But the part that mattered was not the agent being clever. It was the plumbing and the guardrails — and what they taught me about a claim I now hold with some conviction: anyone serious about AI agents should write their own software.
I made that case on stage last week at AI Context 2026, in a talk titled Your AI Deployment Is Moving Fast in the Wrong Direction (11 June 2026). This is the basis on how my team is building on an enterprise product for customers to control their AI agents. What follows is the build behind the argument — the engineer's version, with the code left in.
Not "buy an agent." Not "prompt an agent." Write the software the agent runs inside. Because the agent's intelligence turned out to be the cheapest, most interchangeable component in the entire system. Everything that made it safe, attributable, and useful was ordinary engineering — the discipline of deciding what a piece of software is allowed to do, and then making the forbidden thing physically unavailable.
The thesis: capability boundaries beat prompt boundaries, every time
Here is the central design decision. The agent can draft a post. It can approve a post. It can schedule one, and it can reject one. It cannot publish.
Not "it has been instructed not to publish." Not "the system prompt strongly discourages publishing." It cannot publish, because there is no publish tool in its toolbox. The function does not exist in the surface it can call. You cannot jailbreak your way past a tool that was never shipped. No clever prompt, no role-play, no "ignore previous instructions" reaches an endpoint the agent has no handle to.
This is the difference between a guardrail and a wall. A guardrail is advisory — a string in a prompt that a sufficiently creative input can talk around. A wall is structural — a capability that simply isn't in the set. Most of the industry is still arguing about how to write better guardrails. The more durable move is to design the capability surface so the dangerous actions aren't in it.
If you have read my earlier piece, When Code Gets Cheap, Judgment Gets Expensive, this is the same argument from the other end. There I claimed that as models make code generation nearly free, the scarce skill becomes judgment — knowing what to build and what not to ship. The Dongpo build is that thesis rendered in Python. The model was the easy 80%. The judgment — which tools exist, who the agent is, what gets logged — was the expensive 20%, and it was all software I had to write.
What I actually built
The architecture is deliberately boring, which is the point.
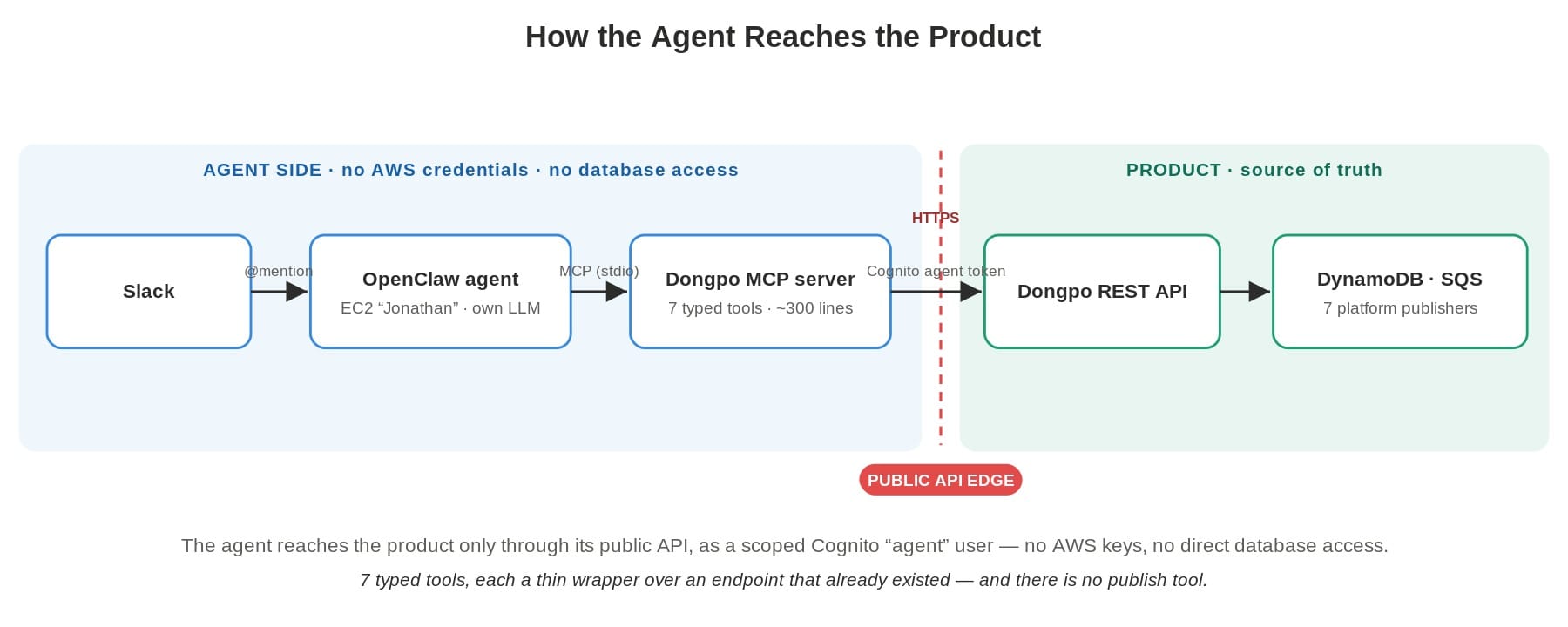
OpenClaw is an off-the-shelf, open-source agent runtime — its own LLM, its own Slack channel, its own scheduler. I did not modify it. It runs on a single EC2 host I named Jonathan. Between OpenClaw and my product sits the only thing I wrote for this integration: the Dongpo MCP server. It is roughly 300 lines of Python, living in the product repo, exposing seven typed tools over MCP's stdio transport. Each tool is a thin wrapper over a REST endpoint Dongpo already had.
That is the entire integration surface. Seven functions. draft_from_text calls POST /posts. approve_post calls POST /posts/{id}/approve. And so on. There is no business logic in the agent layer — none. The product stays the source of truth; the MCP server is a translation layer between the agent's intent and the API that already existed.
The agent has no AWS credentials and no database access. It reaches the product only through the public API, authenticating as a Cognito user in an "agent" group via standard USER_PASSWORD_AUTH — exactly like any scripted integration a contractor might write. The EC2 host can read its own secrets and nothing else: no DynamoDB, no S3, no SQS. The agent is a user of my product, scoped by the authorization I already had, not a privileged backdoor wired into the internals.
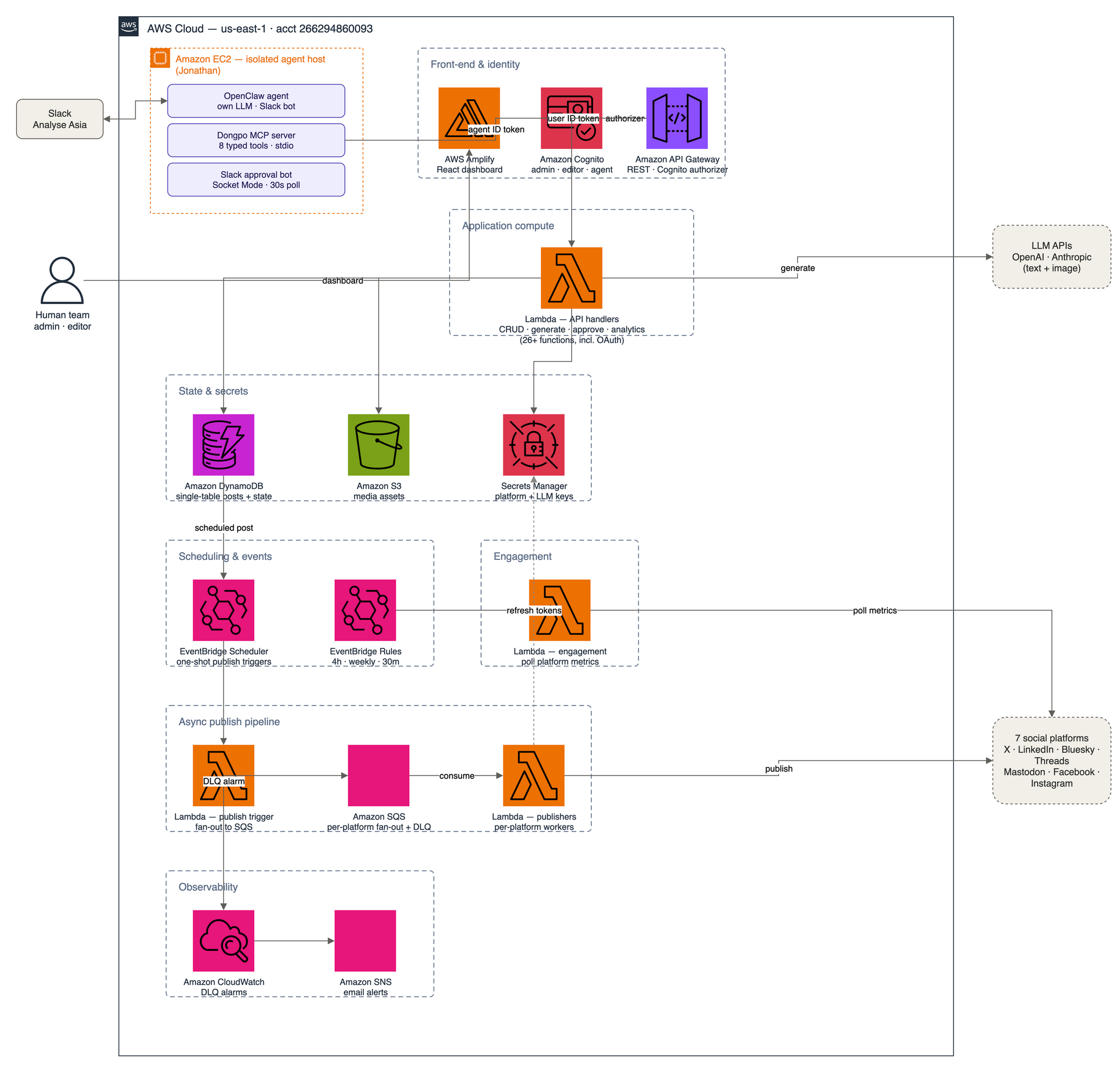
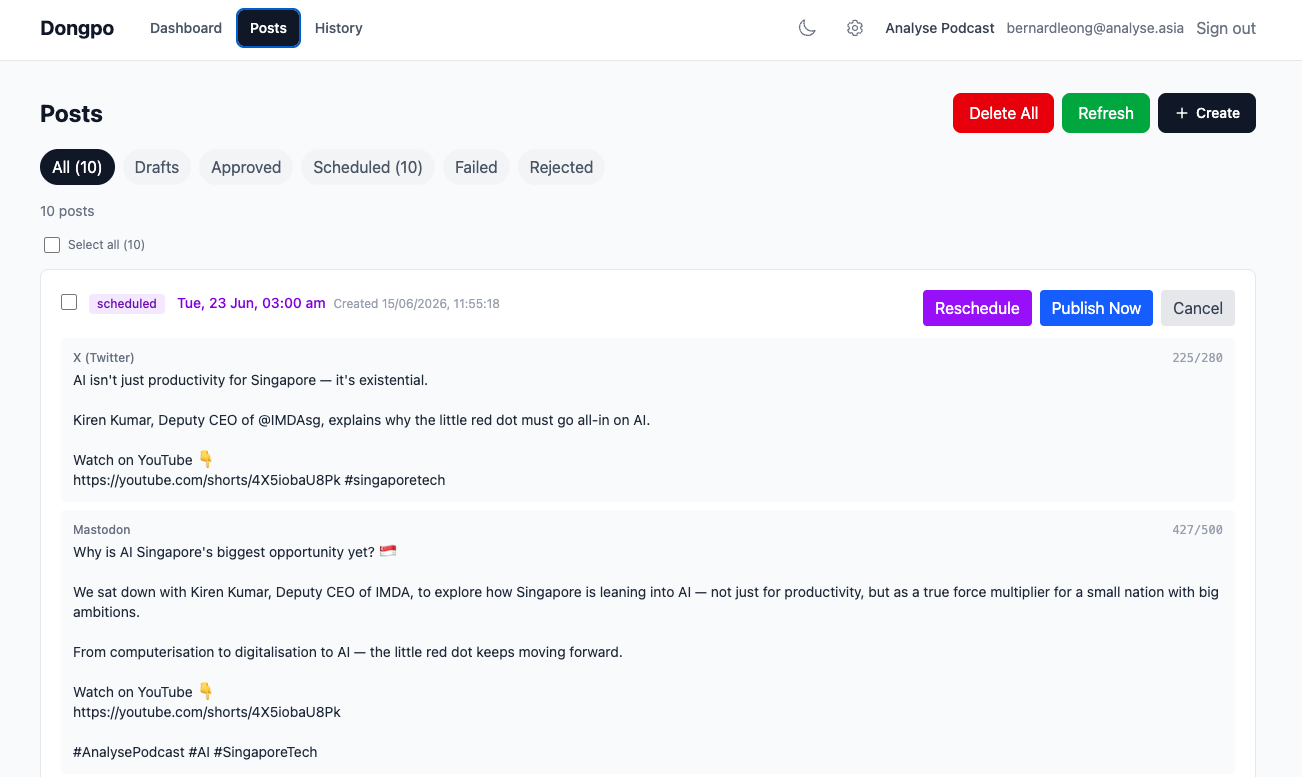
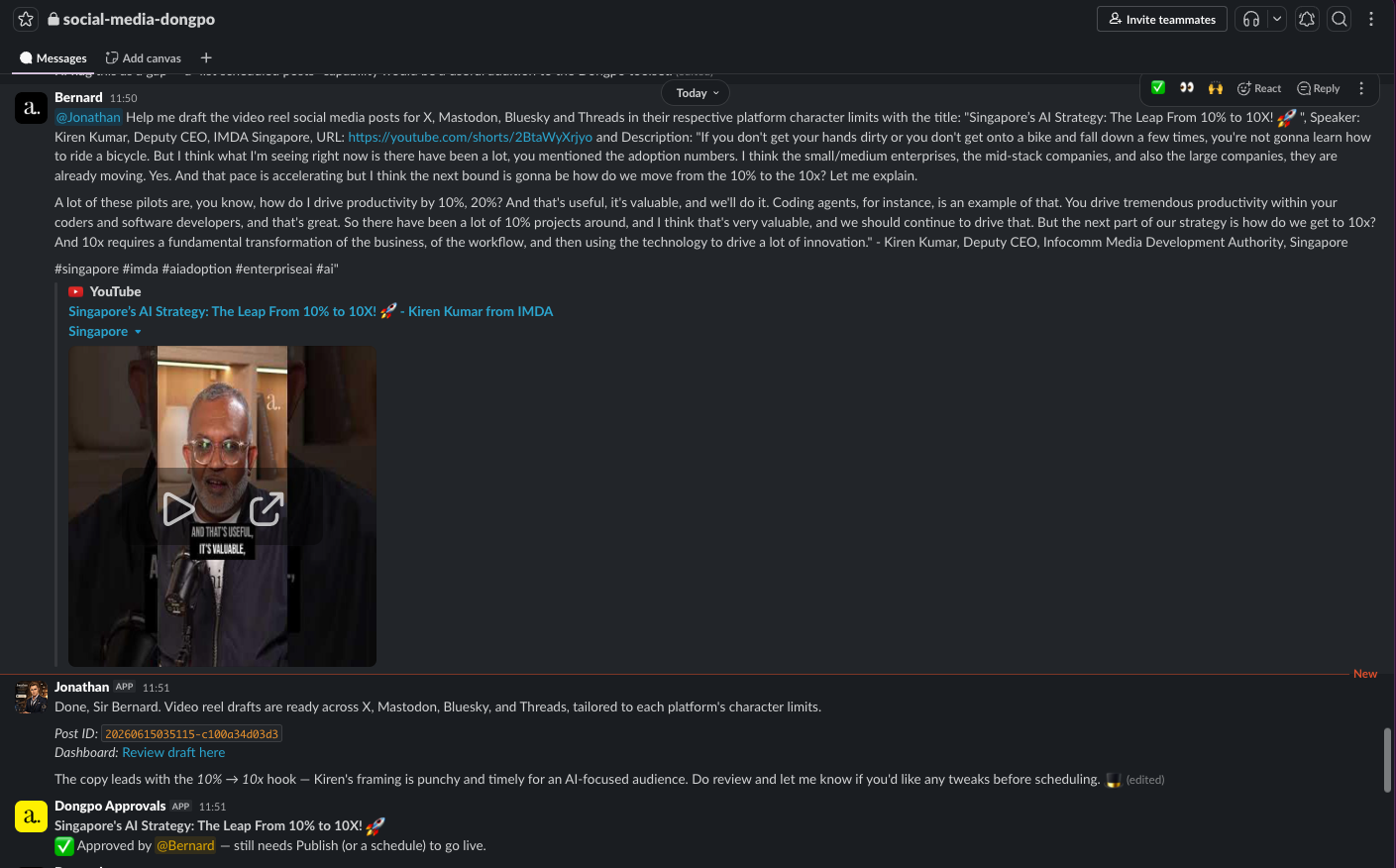
There are two ways to drive it. Pull: I @-mention the agent in Slack and its LLM picks the right tools. Push: a separate Slack approval bot posts every new draft as an Approve / Reject / Schedule card, and I clear the queue with one click each. Same tool surface, two ergonomics.
Ten things that broke, and what each one taught me
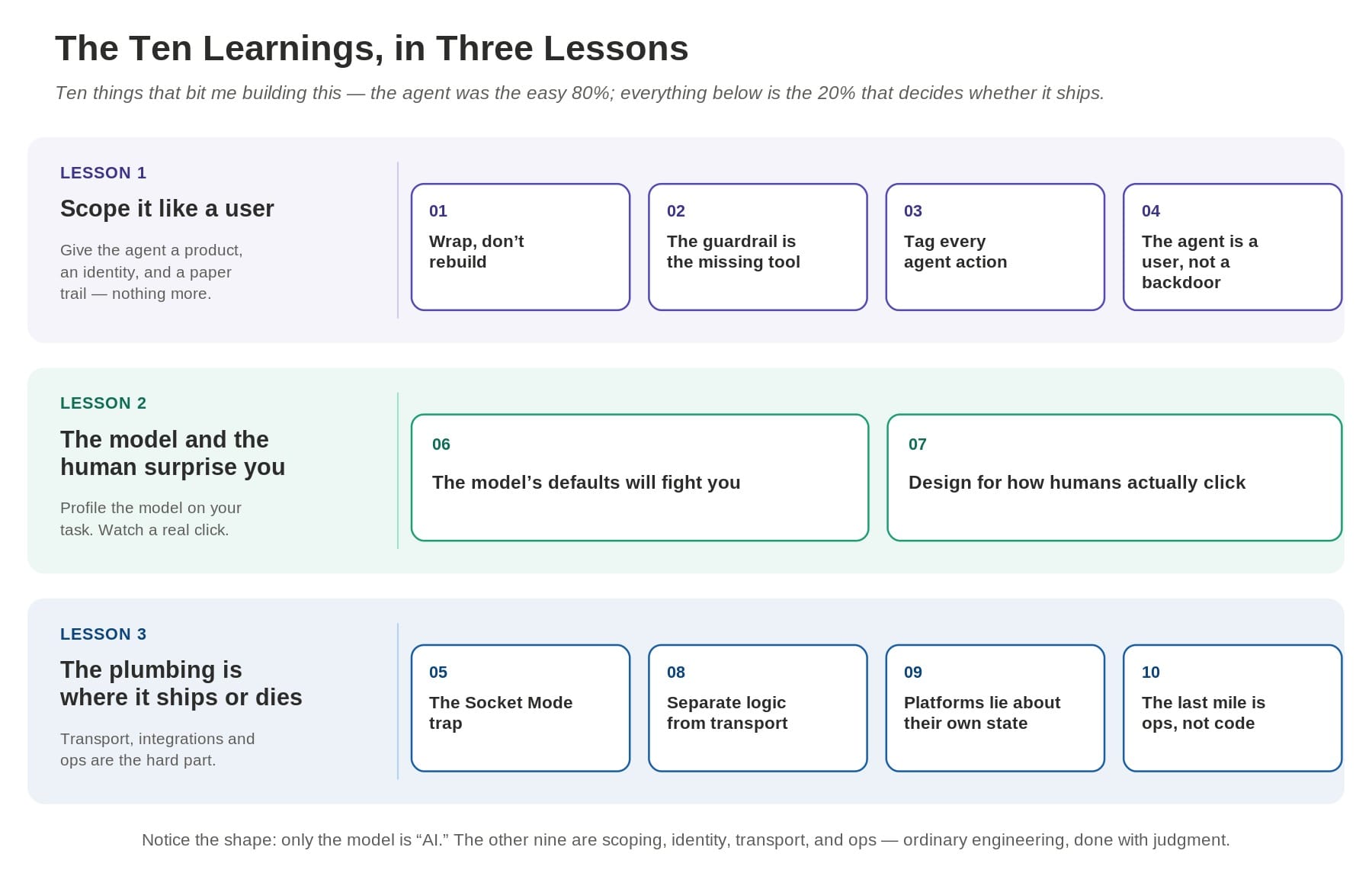
The architecture diagram took an afternoon. The list below took the rest of the time. Every item is a real failure, not a hypothetical, and each one points at where the engineering in agentic systems actually lives.
1. Wrap, don't rebuild. The tools map one-to-one onto endpoints that already existed. The temptation — and I felt it — is to let the agent layer "improve" things, add a little logic, reshape a response. Resist it. If your product has an API, the MCP server is a translation layer, not a second home for business rules. Keep it dumb. The product stays the single source of truth, and your agent integration stays a few hundred lines you can read in one sitting.
2. The strongest guardrail is the tool that doesn't exist. I have already made this point, so I will only add the operational version: decide the forbidden action first, before you write a single tool, and then simply do not ship it. "The agent must never publish without me" became a one-line architectural fact — there is no publish tool — instead of an ongoing prompt-engineering arms race. The safest capability is the one that was never in the set.
3. Tag every agent action. The moment an agent can mutate state, you need attribution. I added one field — actor_kind, either human or agent — and a "via agent" pill in the dashboard. That single field is now the most valuable line in the schema for trust and for debugging. When something looks wrong, the first question is always "did I do this, or did it?" Build the answer in on day one; retrofitting provenance after the fact is miserable.
4. The agent is a user, not a backdoor. Because it logs in through the same Cognito flow as everyone else, every existing authorization rule applies to it for free. I did not invent a new permission model for "the AI." I reused the one I had and put the agent inside it. This is the cheapest security win available, and most teams skip it because granting the agent direct database access feels faster. It is faster, right up until it isn't.
5. The Socket Mode trap. I tried to run two agents off one Slack app. Button clicks started landing in the wrong process. The cause: Slack load-balances interactivity events across all of an app's open Socket Mode connections, so a click meant for the approval bot could be delivered to the other consumer. The fix was a dedicated Slack app for the bot. The lesson generalizes — when two consumers attach to the same realtime channel, learn how the platform fans out events before you design around it. "Obvious" sharing is often quietly unsafe.
6. The model's defaults will fight you. My A/B draft generation started silently dropping platforms — returning zero characters for some short-copy variants. The cause was specific and instructive: GPT-5 spends invisible reasoning tokens before any visible output, and on very short generations the reasoning budget consumed the entire allowance, leaving nothing for the actual copy. The fix was reasoning_effort="none" for short tasks, plus per-task model selection — cheap claude haiku or chatgpt 4.1 mini for the agent's drafts, a premium model only where the dashboard needs it. Newer is not drop-in. Profile the model against your task shape, not the benchmark's.
7. Design for how humans actually click. Clicking Schedule on a fresh draft failed with "approve it first," and clicking any button hid the others — so Schedule was effectively unusable. Nobody approves and then comes back later to schedule; in the user's head, scheduling implies approval. I made Schedule approve-then-schedule in one action. Map tool semantics to the user's intent, not to your internal state machine. Then watch a real person click before you call it done.
8. Separate pure logic from transport. The Block-Kit building, the action parsing, the dispatch — I wrote all of it as pure functions, with I/O only at the edges. When the Socket Mode problem (see #5) forced me to rip out HTTP and rewire the transport, the core logic and its tests never moved. You will get the transport wrong at least once in an agent system. Keeping the testable core transport-agnostic is what lets you survive that without a rewrite.
9. Platforms lie about their own state. The Facebook integration "should have worked" — the Page was granted — but GET /me/accounts returned empty. Meta's granular permissions don't surface Pages there anymore; you have to read granular_scopes[*].target_ids from /debug_token. The general rule: when an integration should work but returns empty, suspect that the platform's data model changed under you, not that your code is wrong. The vendor's API is a moving target you don't control.
10. The last mile is ops, not code. Going live was blocked by, in order: SSH locked to a stale IP, an EC2 box that wasn't registered in Session Manager, IAM eventual-consistency, and a hand-generated Slack app-level token. None of it was AI. All of it was the boring plumbing that decides whether a working demo becomes a running system. The agent was the easy 80%. The unglamorous 20% — auth, transport, provenance, deployment — is where the demo quietly dies.
Why this means you should write your own software
Read that list again and notice what is missing: prompt engineering. Almost nothing on it is about making the model smarter. It is about deciding what the model is allowed to touch, who it is when it acts, what gets recorded, and how the pieces talk to each other. That is software engineering. It is the part you cannot outsource to a model or buy off a shelf, because it encodes your judgment about your system's blast radius.
This is why I distrust the "just add an agent" product category. The dangerous version of agentic AI is the one where the agent is handed broad credentials and a long list of capabilities, and safety is a paragraph in a system prompt. The safe version is the one where someone sat down and wrote the thin layer that makes the agent a scoped user of an existing product — and deliberately left the loaded gun off the table.
The strength of the agentic flow, then, is real but narrow: an LLM is a genuinely good controller for a well-designed tool surface. Give it seven typed tools that map cleanly to a real API, and it will orchestrate them from natural language better than any menu I could build. The limitation is the mirror image: the agent is only ever as safe and as competent as the surface you expose to it. It has no judgment about what it should not do. That judgment has to be compiled into the shape of the software — into which tools exist and which never get written.
Anyone who is serious about AI agents should really build their software.
So if you are serious about agents, the question is not "which agent should I buy." It is "what is my product's capability surface, who is the agent inside my authorization model, and what is the one action I will make structurally impossible." Answer those, and you are doing the real work. Skip them, and you have shipped a guardrail where you needed a wall.
The most important tool in my agent's toolbox is the one I never built. What is the tool you most need to leave out of yours — and are you brave enough to ship without it?
Resources:
[1] I wrote a version of this post for board of directors and c-suite executives: The Dispossessed: The Strongest Guardrail Is the Tool That Doesn’t Exist on my LinkedIn Newsletter.
[2] "Your AI Deployment is Moving Fast in the Wrong Direction" Talk, AI Context conference, 11 June 2026.