



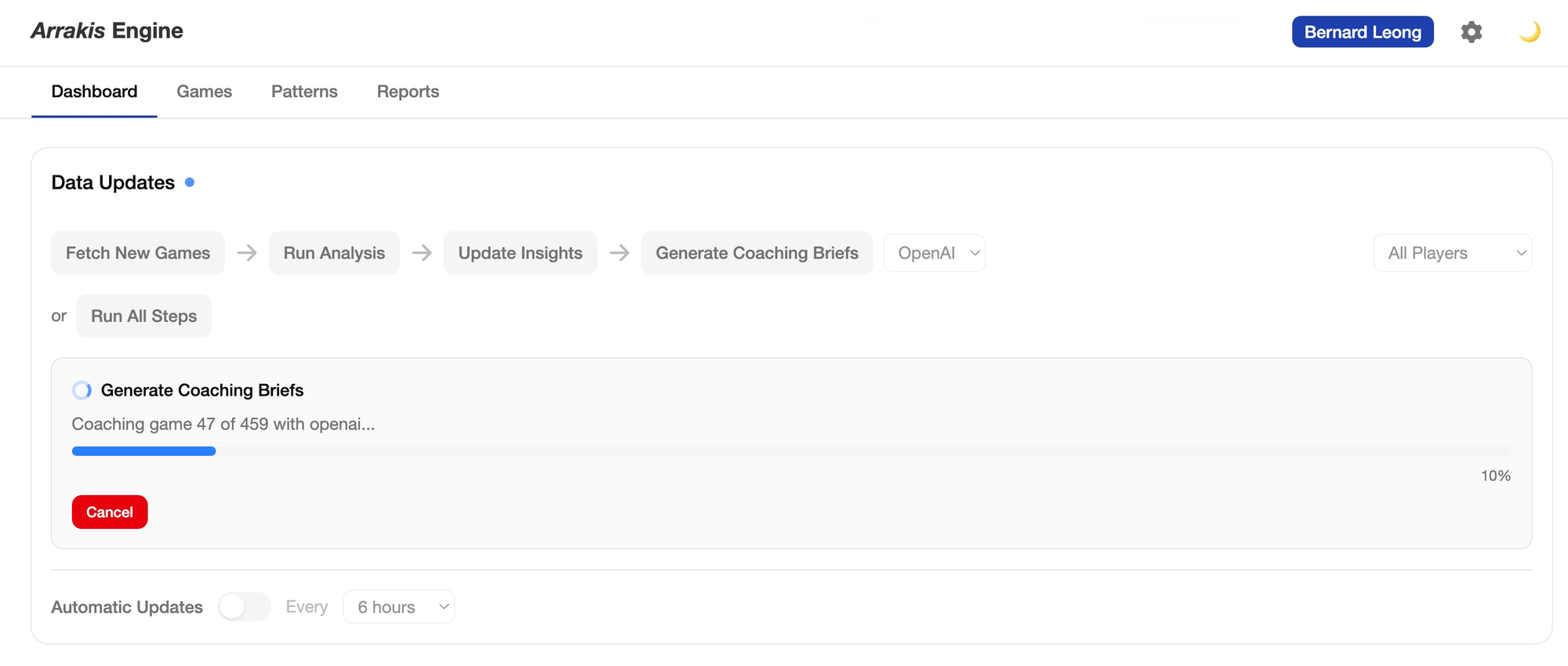
This is the story of building Arrakis Engine, an open-source chess coaching AI that pairs Stockfish's analysis with reasoning LLMs to give children and their parents something chess platforms don't: actual coaching. Released on 7 April 2026. I will talk about the lessons learnt while building Arrakis over the weekends and sometimes in the chess competitions where I sat and waited for my son. It's an honest account of what AI-assisted development requires from the human in the room on building any app to be production ready.
Every evening during the build, I had the same thought: this is not good enough. Not in a discouraging way. More like a calibration device. The product wasn't done, the tests weren't complete, the large language models (LLMs) output had problems I hadn't fully solved yet — and that persistent dissatisfaction kept me honest. It kept me testing edge cases I might otherwise have skipped, checking whether metrics I'd implemented were actually correct, and getting real feedback from the coaches and other chess parents rather than shipping something that looked finished but wasn't. That instinct — to stay uncomfortable until the system earns your confidence — turned out to be the most important thing I brought to 18 days of AI pair-programmed product development. More important than the architecture. More important than the tools.
The gap that started everything
I have a rule in the my household that all my three children has to beat me in chess before they reached 12. My eldest daughter Eleanor beat me at 9 years old and she did not have a chess coach. She chose to learn either lessons from Chess.com and from her school friends in the Rosyth School chess club. She eventually come up with different ways to beat me all with her own merit. She shared how she beat me to my younger children with the following comment, "All you just need to do is take away daddy's queen." I am proud of Eleanor's resilience and grit and ability to learn fast. My second child, Evan, started playing competitive chess at 7 years old after a humiliating defeat. He beat me at the age of 7 and these days, I could not even win a single game at all. Within a year, through the help of a private coach and advice from his school coach and other chess parents in the Rosyth School, playing at the Fernvale Chess Club every Friday and advice from an old friend (with his son used to playing competitive chess then switch to tennis), he progressed well, being part of the only unrated team to win overall 4th in the National Schools Teams (NST) under 8 championships and 2nd in the North zone in Singapore. While he has achieved results to my surprise, he has a long growth path ahead of him because I often tell them that to be good at something is easy, but to be great at something requires deliberate effort and focus. My youngest daughter, Estella beat me at 5 years old and would be starting her own chess journey very soon at the age of 7 this year. The cycle repeats itself for me one more time.

When I am with my son for every competitive game, even if I bring my laptop to work while waiting for him, I ended up focusing on how to calm him down after every loss. Even if he gradually won more and more games and be less emotional about the losses, I know that he will eventually hit a wall given that he does not record every game like the best players do. I have read enough chess biographies and spoken to parents how the best players in the space operate. However, I have to be clear, the intention is not to make a grandmaster or even anything remotely close to a national player, but to help him understand what it takes to be great at something with both talent and grit. Eventually, my children will find what they loved someday like I do with theoretical physics that extended my path to artificial intelligence and quantum computing and then excel to the next level which I can never achieve given the limits I have reached despite the odds I faced then.
Chess teach many lessons to the kids in their early lives. The first is to be able to cope with losses in the short term and always looking forward to the next game. The second is that if you lose the game and able to go through the game review with recording, you learn a lesson smiliar to agentic AI design pattern called reflection. Through reflection, you learned and reviewed from your mistakes and get better. Third, chess helps the child to develop how to think 5 to 10 steps ahead. I am not a typical Singaporean parent. There are a few games which I insisted that my children should learn before they reach 18: chess, poker, go and mahjong. Poker and mahjong are games where they have to understand short term tradeoffs versus chess and go are games where they need to think long term and ahead against the challenges which will come to them later in their lives.
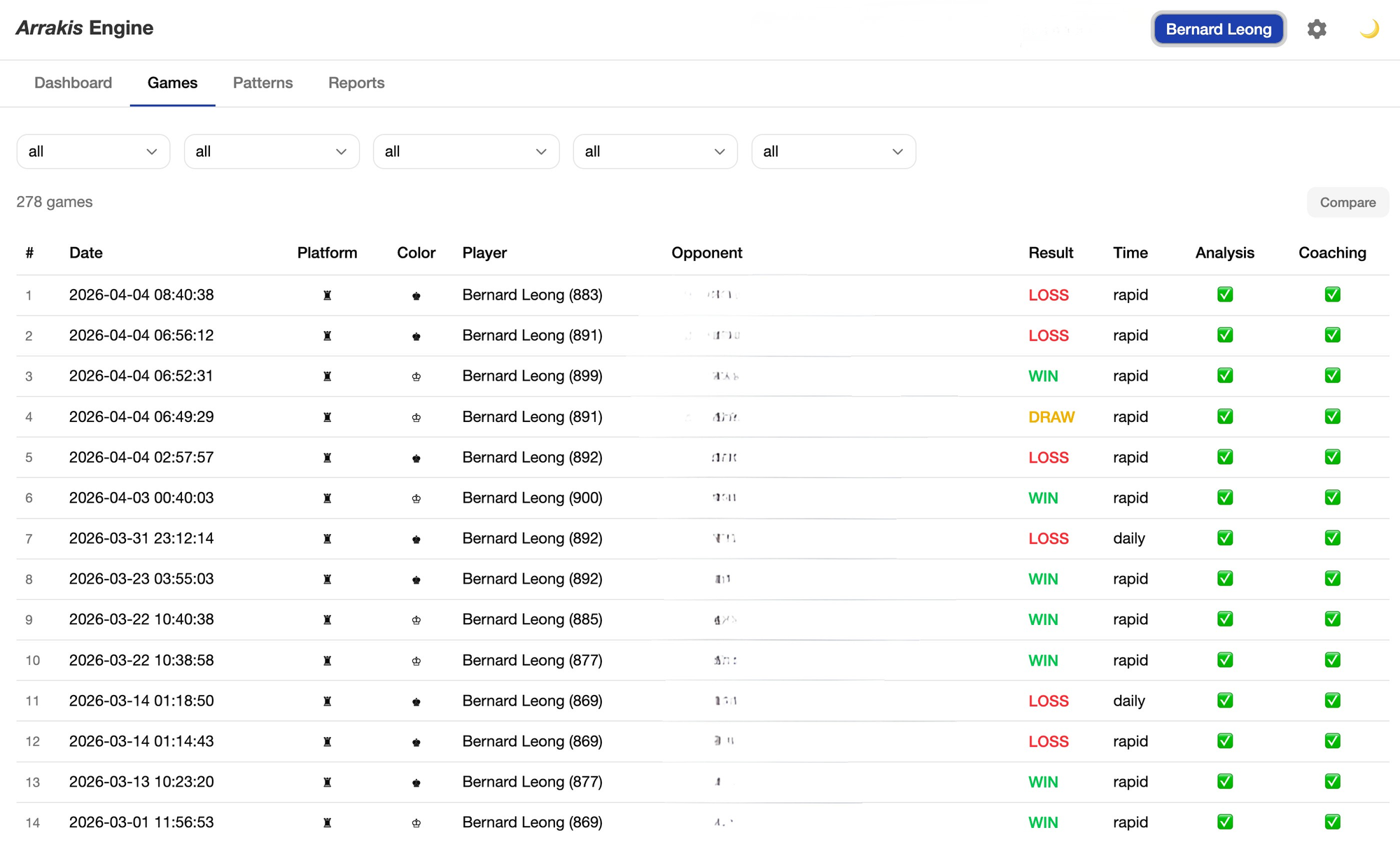
Evan managed to get away at first by asking his opponent with the consent that he can take a picture of it. He has started recording recently after a lot of nudging and with advice from his school and private coach helping him to review the game. That comes to the story why I ended up building Arrakis engine but to assist him in games that he has lost in chess.com and lichess and also a tool to augment the coaches on how to advise him based on his strengths and weaknesses. After every game online, the ritual is the same: open Chess.com or Lichess, run the game review, stare at a graph that swings between green and red. The app marks blunders. It suggests best moves. It gives you centipawn numbers that mean nothing to a nine-year-old.
What an online chess system does not do is to coach.
A good chess coach doesn't just identify errors — they reason about them. "You've been rushing in the middlegame all week. Last Tuesday you had a similar position and gave it away because you didn't check your opponent's best reply. Let's slow down and practice that." That's a fundamentally different task from evaluation. It requires connecting patterns across games, adapting language for the student's age and level, and building on prior lessons so you're not repeating the same advice session after session.
The gap between analytical truth and pedagogical wisdom is large. Chess engines are extraordinary at the first and useless at the second. When reasoning large language models (LLMs) in AI like Claude Opus 4.6, ChatGPT 5.4 or Deepseek R1 thinking mode arrived — models with genuine chain-of-thought capability rather than pattern-matched response generation — I thought the pieces might finally be in place to bridge that gap. Nobody had connected Stockfish's precision to an LLM's reasoning in a way that would work for a parent sitting with their child after a game. So I decided to find out if I could build it.
Start simple. Earn the complexity.
I want to be precise about what I mean by AI pair programming. I deliberately avoid the term vibecoding, because I started coding at 9 years old being fluent in COBOL and C by 12 years old. Of course, building an AI-native company and teaching generative AI to both engineers and business executives, I have changed how I code. Every major technological change has forced me to changed my practices in coding. By this time, I code for fun but directed product and technical teams to build products at lightning speeds. Of course, I didn't type natural language prompts and watch a finished application materialise until three years ago. As the technology grew, I have started to change how I program from python to English.
I worked with Claude Code — Anthropic's AI coding assistant that operates directly in your terminal — as a pair programmer: I directed the architecture, made the product decisions, and iterated on design. Claude Code implemented, refactored, debugged, and wrote tests alongside me. Over 300+ prompts across the 18 days. Think of it as having a tireless senior engineer who can context-switch instantly between Python, TypeScript, SQL, and CSS — but who needs you to know what you're building and why.

The first decision I made was to start simple only with basic hypertext markup language [or HTML in short] and python. Not because simplicity was the end goal, but because I wanted to understand the problem before I optimised a solution for it. I avoided using javascript libraries and the better languages which have evolved for example, typescript, tailwind CSS, javascript libraries such as node.js, react.js and node.js. The reason is that I am not familiar with the languages and my aim is to switch to these with AI coding once I have a proper understanding of what I was trying to achieve with a simple build.
On the first weekend — three version milestones on day one — I had a working command-line tool in Python. It fetched games from Chess.com, ran every move through Stockfish at depth 22, and sent the analysis to an LLM with a carefully structured prompt. The output was a coaching brief: game narrative, key lesson, critical moments, a personal letter to the player. No dashboard, no database UI, no bells. Just a pipeline I could test, watch fail, and fix. One thing I did do, was to prompt the LLM to provide coaching guidance based on the age of the child.
This decision — start with CLI before building any interface — paid dividends later. When I moved to a web dashboard, I was adding a view onto a working system, not trying to build the system and the interface simultaneously. One practice I adopted early and never abandoned: before Claude Code wrote any significant new component, I asked it to ask me clarifying questions first. This sounds minor. It isn't. An AI pair programmer will make assumptions about what you want and implement against those assumptions competently. The result looks correct — the code runs, the tests pass — but the underlying design choices may not be the ones you would have made had you been asked explicitly. When you require the AI to surface its assumptions as questions before writing a line of code, two things happen. First, you catch misalignments before they're baked into a codebase you now have to unpick. Second, and more importantly, the questions themselves force you to be precise about what you actually want — which is frequently less clear than you think it is until someone asks you directly.
In practice, this meant that before implementing the coaching history injection, I didn't just say "make the LLM remember previous sessions." I worked through the AI's questions: How many sessions back? Should the history be injected as structured data or as narrative summaries? Should the prompt tell the model explicitly what it previously recommended, or should it provide the raw coaching output and let the model draw its own connections? Each question produced a design decision I had to own. The implementation that followed was mine — the AI had just made sure of it.
This discipline matters more, not less, as codebases grow. It's easy to maintain coherent architecture when everything fits in your head. Past a few thousand lines, the AI's assumptions start accumulating in corners you haven't visited recently. Requiring clarifying questions is a forcing function that keeps the design decisions in the hands of the person who understands the product, not the tool that's implementing it.
The web dashboard started with Python's built-in HTTP server and basic HTML. Functional, not beautiful. When I moved to a Next.js and React frontend on day seven, it wasn't because I'd planned to — it was because the system had earned that complexity. The data model was solid, the pipeline worked, the coaching output was worth displaying properly. The rewrite wasn't starting over; it was investing in a foundation that had proved itself.
That progression — Python CLI to Python HTTP server to Next.js — mirrors how I think about technical architecture generally. Complexity should be earned, not assumed upfront.
The problem with "good enough" LLM output
The hardest engineering problem in this project wasn't the Stockfish integration or the Next.js component architecture. It was the LLM coaching layer — specifically, the repetition problem.
The first version of the coaching prompt produced output that looked reasonable on first read. The narrative was coherent, the advice was specific. But when I ran it across multiple games for the same player, a pattern emerged: the LLM was giving essentially the same advice, game after game. Different games, different mistakes, same coaching letter. "Work on your endgames. Practice tactical puzzles." It had found a local optimum and was stuck there. This is a failure mode that's easy to miss if you're testing on a single game and calling it done. I wasn't, which is why I caught it — but it required rebuilding the prompt from the ground up.
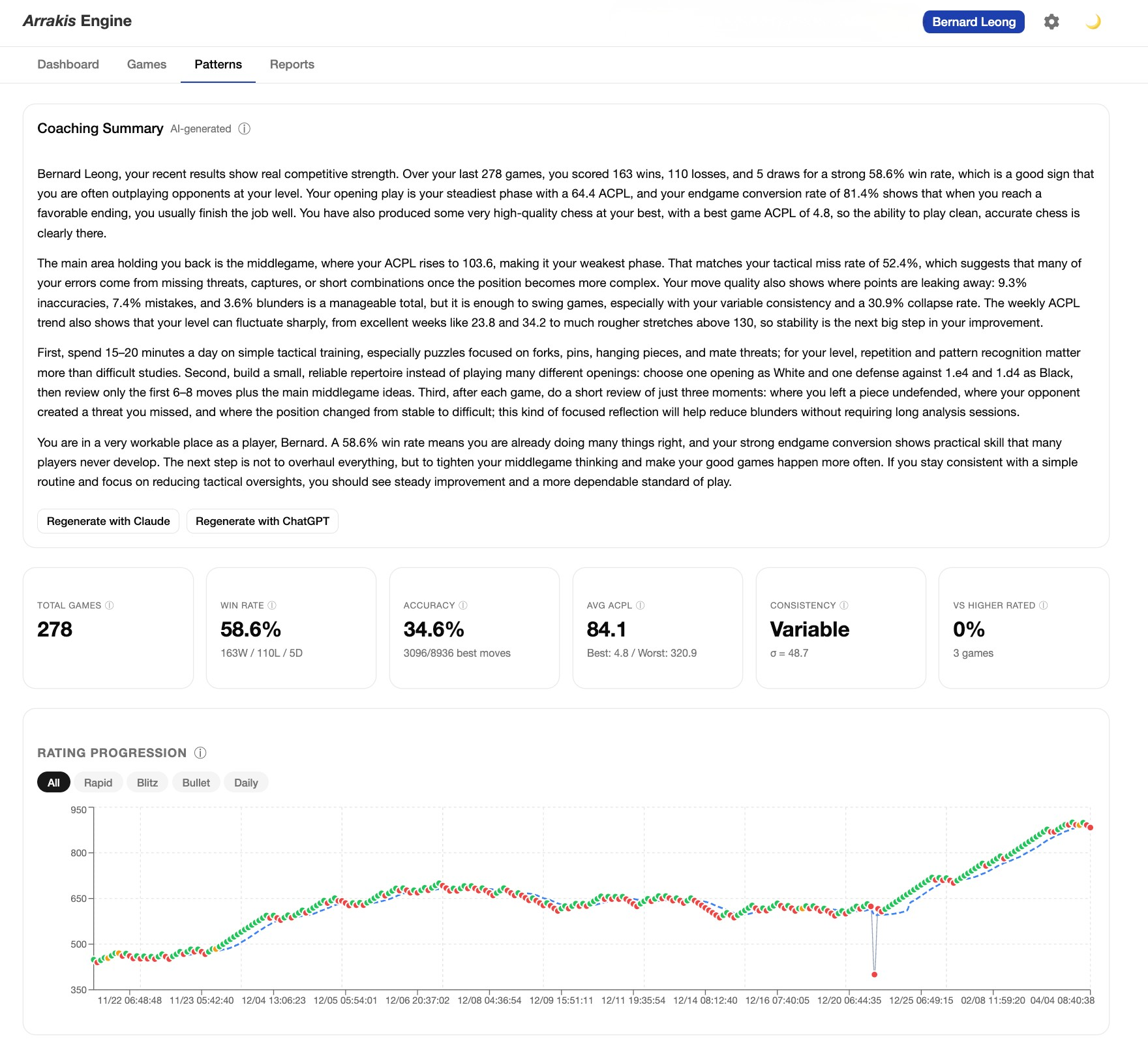
The solution had two parts. First, coaching history injection: I restructured the prompt to pass in the last five games' coaching summaries explicitly, so the LLM knows what it has already said and can deliberately build on it rather than repeat it. Second, explicit variety instructions in the prompt itself: the system is told, directly, to avoid formulaic output and to find the specific lesson this particular game teaches — not the general lesson this type of position suggests.
The difference was substantial. With coaching history in context, the LLM starts making connections: "Last week we worked on not rushing in winning positions. In this game you actually did that well — you converted a rook endgame cleanly. The problem today was earlier: you gave up a pawn in the opening for insufficient compensation." That's a coach tracking a student's development. That required understanding what the prompt was and wasn't doing and rebuilding it with a different architecture.
I learned something more general: LLM output that looks good in isolation often degrades when you run it at scale across a real dataset. The evaluation discipline — running the pipeline on enough games to surface pattern failures — is as important as the prompt engineering itself.
The real distribution of time
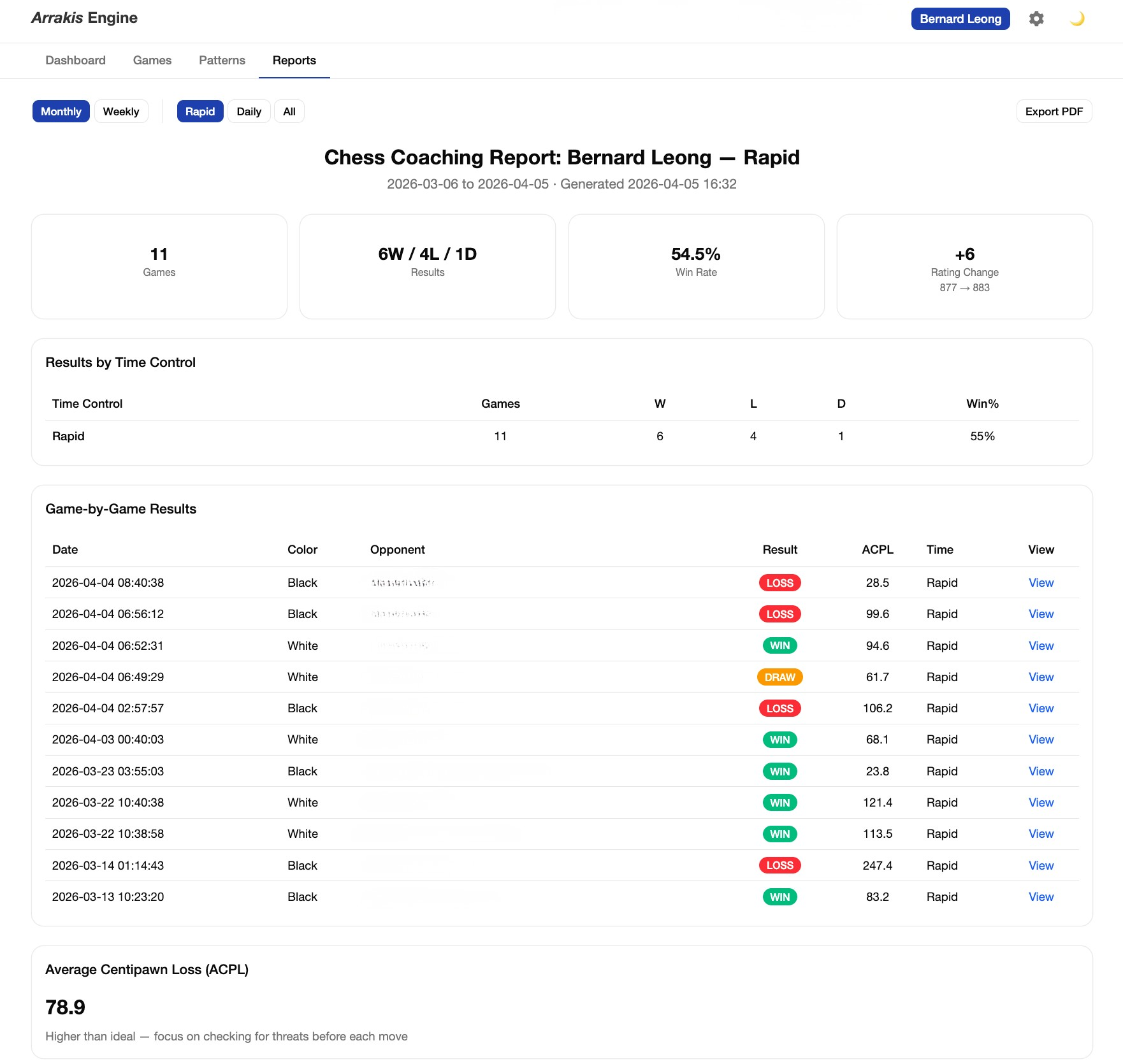
Here is what the 18 days actually looked like, roughly: 25% planning and architecture, 50% testing and validation, 25% building features.
That ratio surprises people. The received narrative about AI pair programming is that it's about building faster. It is — but "faster" means faster iteration, not less time spent on quality. If anything, AI-generated code requires more deliberate testing because you didn't write it line by line and therefore don't carry the same intuitive model of what it does.
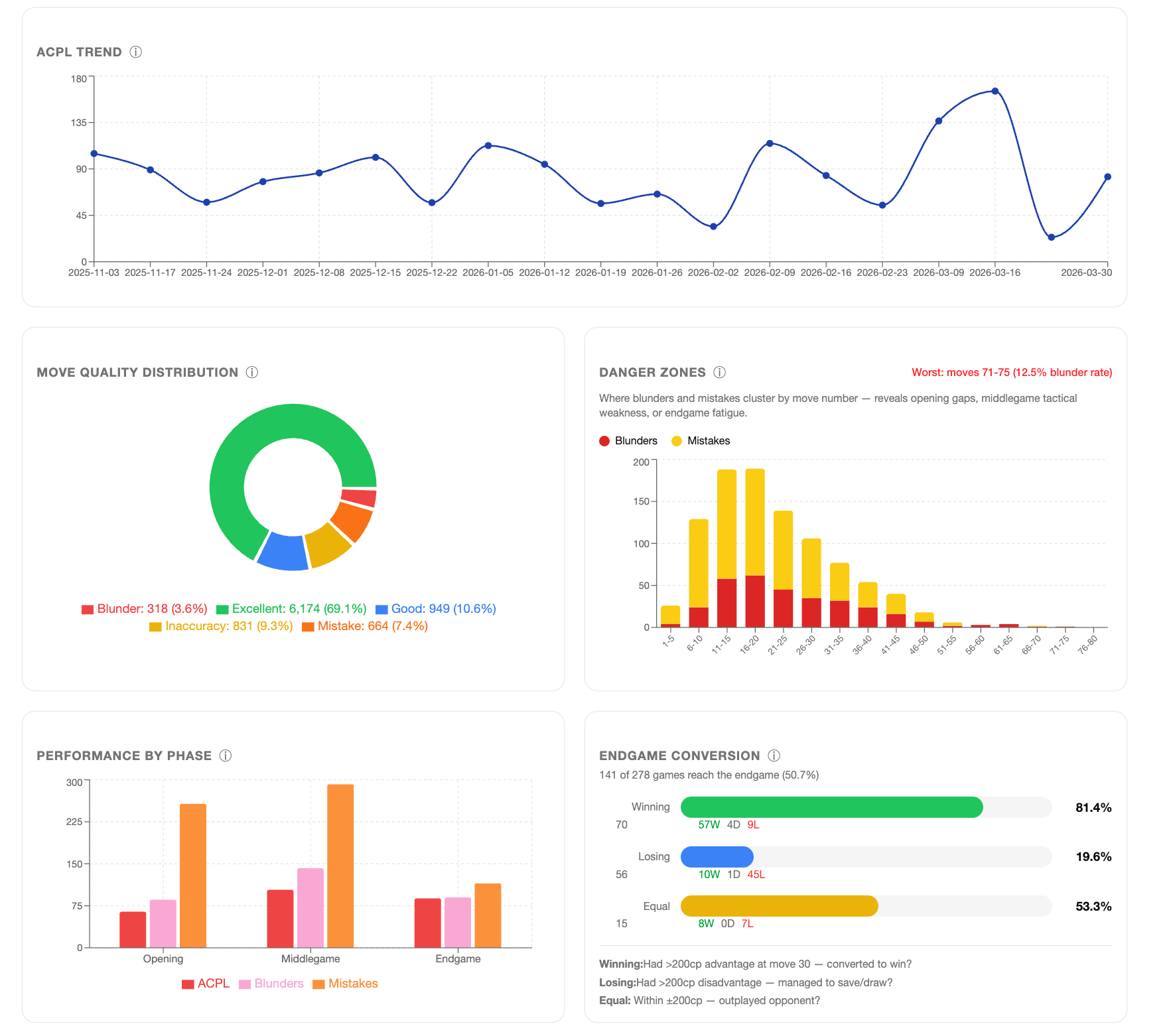
I started with zero tests and ended with 240: 227 unit tests, Stockfish integration tests, live LLM API tests, and a full end-to-end pipeline test. The testing wasn't a phase at the end — it ran throughout, and it caught things I would otherwise have shipped. The win probability formula, the average centipawn loss (or ACPL) capping at ±1000 centipawns (the same standard used by Lichess and Chess.com), the move classification thresholds by player tier — I checked all of these against the source data to verify my implementation was correct, not just functional.
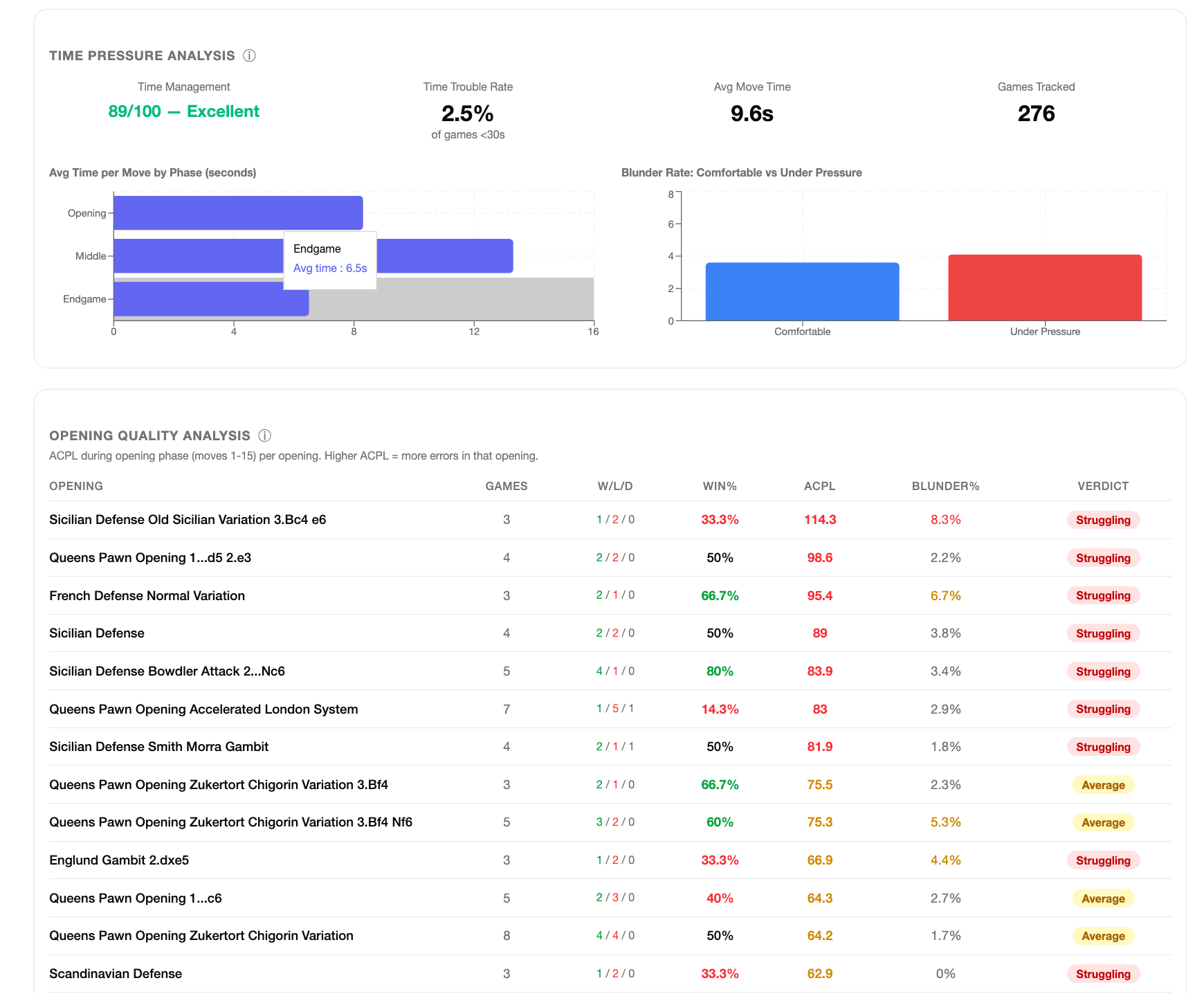
That last point matters. At one point my intuition told me a metric might be wrong. Not that the code had a bug — that the underlying calculation might not match what it was supposed to measure. I went back to the Lichess methodology, verified the formula, and found the implementation was correct. But the instinct to check is part of what makes software trustworthy rather than merely working.
I also got external validation by showing the product in its half baked form to the coaches and the parents. It is great when some chess parents are in the software engineering space and I suspect there is a correlation there on why our kids are into chess. Chess parents and coaches provided feedback to the early versions and gave feedback on what was actually useful versus what looked sophisticated but didn't help. That feedback shaped decisions: which visualisations earned space on the dashboard, what the coaching letter needed to say differently for a seven-year-old versus a fourteen-year-old, how to structure the weekly report for a coach preparing a lesson.
None of that can be automated. It requires knowing the domain, knowing your users, and being willing to act on what they tell you.
What reasoning models actually change
The technical decision with the most impact on this project wasn't the architecture or the testing framework. It was the requirement that the coaching layer only runs on reasoning models — LLMs with genuine chain-of-thought capability — and explicitly refuses to use instruction-tuned models that produce shallow output.
The difference is stark. When I tested coaching with a standard model, the output was generic: "Avoid blunders. Practice endgames." True advice, useful to no one. When I switched to a reasoning model, the quality transformed. The LLM traces the position: "On move 23, you had Nxe5 which wins the exchange. But you played Qd2 — I think you were worried about the back rank threat. But after Nxe5, your opponent's best reply is Qd7, and your back rank is safe because your rook covers it." That's a model working through a position, not matching a pattern.
The reason is architectural. Chess coaching requires multi-step reasoning at every level: tracing tactical sequences, connecting patterns across games, calibrating language for a child's age, producing reliable structured JSON. Instruction-tuned models are optimised for response fluency, not for the kind of deliberate inference that coaching demands. Reasoning models do the hard work by design.
The implication extends well beyond chess. Any domain where an AI needs to produce advice that's grounded in a specific situation — medical, legal, financial, engineering — will see the same quality gap. The question for builders is whether your use case actually needs reasoning capability or whether pattern-matching is sufficient. Getting that assessment wrong in either direction is expensive.
What this means for technical leadership
I'm a CEO who builds. I've been deliberate about that — maintaining genuine technical capability, not just technical fluency — because I think it matters for how you lead AI implementation work. Arrakis Engine is partly a personal project, partly a stress test of my own thesis.
What I found is that AI pair programming doesn't lower the bar for technical depth. It raises the bar for judgment.
When implementation is cheap, the decisions that matter are architectural: what to build, in what order, with what constraints. The choice to start with a Python CLI and earn the Next.js frontend. The decision to cap ACPL at ±1000 centipawns rather than using raw engine scores. The design of the coaching prompt to include history and variety. The practice of requiring the AI to ask clarifying questions before implementing anything significant. The call to require reasoning models and document why. These are judgment calls that require domain expertise and product experience — neither of which an AI pair programmer provides.
The "solo founder plus AI" model is real. But the differentiator isn't prompting skill. It's knowing your problem well enough to make good decisions faster than you'd otherwise be able to test them.
Evan asked me last week for "more details on my openings from his recent competition." That's user feedback I'll act on — it'll probably become the next feature priority. The most important thing I built in 18 days is a system good enough that its users want more of it. I have open sourced this because I am aware that many parents might need a tool like this to help their children.
Arrakis Engine is open source: github.com/bleongcw/Arrakis_Engine
Acknowledgments: I thank the chess parents from Rosyth School specifically Gan Ying Kiat and Edward Teo where we discussed the different chess engines that led to me building Arrakis and Fernvale Chess Club, the coaches: Mr Lee Peng Keong and Arlan Cabe and many others who have provided feedback on Arrakis Engine.